PythonでExcelの使い方についてです。
この記事の内容はコチラです
- PythonからExcelのデータをすべて取得する
- 「Sheet1」に存在するすべてのデータを取得する
今回は、Excelのデータをすべて取得する方法を解説します。
Excelのデータをすべて取得する
構文
import openpyxl
# ブックを取得
ブック変数 = openpyxl.load_workbook('ファイル')
# シートを取得
シート変数 = ブック変数['シート']
# セルを1つずつ取得
for セル変数1 in tuple(シート変数.rows もしくは シート変数.columns):
for セル変数2 in セル変数1:
セル変数2.value
PythonでExcel操作をするには、「openPyXl」パッケージが便利です。「openPyXl」を事前にダウンロード・インストールしておく必要があります。
参照:外部パッケージ OpenPyXLをインストールする方法
「rows」「columns」は「タプル」で行or列が構成されます。そのタプル内でさらにタプルで行or列が構成される2重タプルになっています。
なので1行or1列ごとに取得し、その1行or1列をさらに取得すれば、セルのデータを取得することができます。
サンプルデータ
サンプルデータとして、今回はこのようなEXCELデータを使用します。
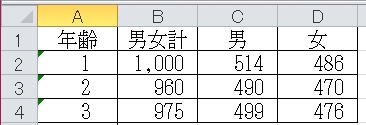
例1. Excelのセルをすべて取得する(行が基準)
import openpyxl
# ブックを取得
book = openpyxl.load_workbook('C:\\pg\\人口一覧.xlsx')
# シートを取得
sheet = book['Sheet1']
# セル番地を取得
for cells in tuple(sheet.rows):
for cell in cells:
print(cell.value)
#[結果] 年齢
#[結果] 男女計
#[結果] 男
#[結果] 女
#[結果] 1
#[結果] 1000
#[結果] 514
#[結果] 486
#[結果] 2 ※以下省略
この例では、「Sheet1」に含まれるデータをすべて取得しました。
「tuple(sheet.rows)」で1行ごとに取得し、その1行をさらに列毎に取得して、セルの値を取得しました。
例2. Excelのセルをすべて取得する(列が基準)
import openpyxl
# ブックを取得
book = openpyxl.load_workbook('C:\\pg\\人口一覧.xlsx')
# シートを取得
sheet = book['Sheet1']
# セル番地を取得
for cells in tuple(sheet.columns):
for cell in cells:
print(cell.value)
#[結果] 年齢
#[結果] 1
#[結果] 2
#[結果] 3
#[結果] 男女計
#[結果] 1000
#[結果] 960
#[結果] 975 ※以下省略
例1と同じくセルを1つずつ取得しました。取得するデータは同じですが、順番が違います。例2は列を基準に取得しました。例1との違いに注意してください。
「tuple(sheet.columns)」で1列ごとに分解し、その1列をさらに行毎に分解して、セルの値を取得しました。
これでEXCELのセルデータをすべて取得することができました。
参照:https://openpyxl.readthedocs.io/en/stable/#
以上、PythonでExcelのデータをすべて取得する方法でした。
● Python初心者におすすめ!
Python学習方法に関する記事です。読まないと損するかも。

コメント