PythonのRSSの取得方法について。
この記事の内容はコチラです
- RSSを取得する
- スクレイピングの使い方を知る
- Beautiful Soupの使い方を知る
今回は、このRSSの配信内容をPythonを使って取得してみます。
RSSからタイトルを取得する(Beautiful Soup)
PythonではRSSからタイトルなどを取り出す(スクレイピング)ことができます。
RSSはWEBサイトやブログなどで配信された情報を通知する機能です。
事前準備
PythonでRSSをスクレイピングするには、外部のモジュールを使用します。
WEBにかんたんに接続できる「Requests」、簡単にスクレイピングできる「Beautiful Soup」を使用します。
インストールされていない場合は事前にインストールする必要があります。
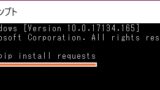
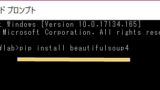
Yahooニュースをスクレイピングする
今回は有名なYahooニュースのRSSをスクレイピングしてみます。
Yahooニュースはカテゴリだけでも多数あります。
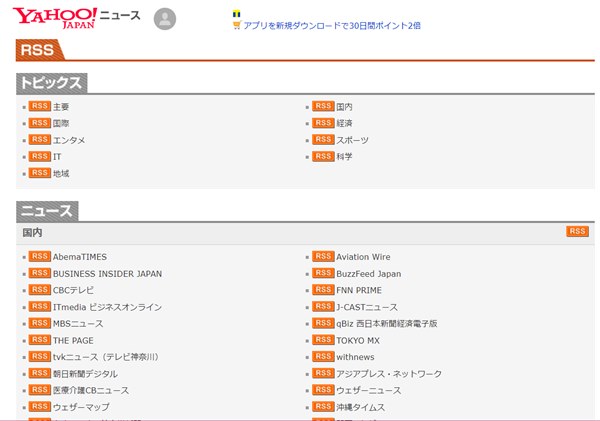
RSSのリストはこちらを参照してみてください。
YahooのRSS:https://headlines.yahoo.co.jp/rss/list
今回はその中で「ITmedia NEWS」のRSSを取得し、タイトルをスクレイピングします。「ITmedia NEWS」のRSSはこちらです。
ITmedia NEWSのRSS: https://headlines.yahoo.co.jp/rss/zdn_n-c_sci.xml
YahooニュースのRSSを確認する
YahooニュースのRSSを確認してみます。

YahooニュースのRSSを確認するとXMLファイルです。XMLをみると「item」の「title」に記事のタイトルがつけられています。これをスクレイピングすればよさそうですね。
RSSをスクレイピングする
import requests
from bs4 import BeautifulSoup
url = 'https://headlines.yahoo.co.jp/rss/zdn_n-c_sci.xml'
# Yahooへ接続
req = requests.get(url)
# BeautifulSoupで解析
txt= BeautifulSoup(req.text, 'html.parser')
# スクレイピング
for rss in txt.findAll('item'):
rss.title.string
# [結果]'ウェザーニューズ、5分ごとの天気予報可能に\u3000「途中省略(ITmedia NEWS)'
# [結果]'4年前の「AIがチューリングテスト合格」途中省略(ITmedia NEWS)'
# [結果]'サッカーみたいな“エアホッケー”\u3000途中省略(ITmedia NEWS)'
# [結果]'空を飛びながら体幹トレーニング\u3000VR途中省略(ITmedia NEWS)'
まず最初に「from bs4 import BeautifulSoup」でBeautifulSoupをインポートします。「requests」もインポートします。
「ITmedia NEWS」のRSSのアドレスを「requests.get」に渡し、RSS情報を変数「req」に取得します。これでRSSの情報は取得できました。
次に、RSSデータから必要なデータだけを取り出します。今回は更新された記事のタイトル一覧を取得します。
txt= BeautifulSoup(req.text, 'html.parser')
このコードでは「Beautiful Soup」にRSSデータを渡して解析します。「req.text」がRSSデータです。「html.parser」はHTMLを解析するクラスです。
for rss in txt.findAll('item'):
rss.title.string
スクレイピングするには「Beautiful Soup」の「findAll」を使います。ここでは「txt.findAll(‘item’)」とし、「Beautiful Soup」で解析した「txt」から「item」タグをスクレイピングしました。
そして「item」タグから「rss.title.string」でタイトルタグをスクレイピングしました。
以上、Python RSSからタイトルを取り出す方法(Beautiful Soup)でした。

コメント